สถิติเป็นวิชาที่เกี่ยวกับการรวบรวม จัดระเบียบ วิเคราะห์ และตีความข้อมูล เพื่อนำไปสู่การตัดสินใจและสรุปผลที่มีหลักเกณฑ์ สถิติมีบทบาทสำคัญในการศึกษา วิจัย และการตัดสินใจในหลากหลายสาขา เช่น วิทยาศาสตร์ สังคมศาสตร์ ธุรกิจ การแพทย์และการตัดสินใจต่างในชีวิตประจำวัน การเรียนรู้สถิติจะช่วยให้เราเข้าใจโลกและตัดสินใจได้อย่างมีเหตุผลมากขึ้น
Essential Statistics
Why we start to learn statistics? Case analysis of listening to Lisa’s music Started Statistic Sample Statistical Case Case Cooking Food Case Stock Case Relationship Sampling Probability Sampling Simple Random Sampling Case Lottery Case Simple Random Sampling in Excel Systematic Random Sampling Cluster random Sampling Stratified Random Sampling Case Beer Case Population Census Non Probability Sampling Convenience Sampling Case Google Form Snowball Sampling Case Ivory Data Collection Sample Size Diminish Return Margin of Error vs Sample Size vs Budget Confidence Level vs Sample Size Descriptive Stat Central tendency Mean Median Mode Spread Tendency Position Process of Distribution Normal Distribution Skewed Left Distribution Skewed Right Distribution Outlier Why we start to learn statistics?
โดยวิชาสถิติเริ่มต้นมีมาตั้งแต่ 300-400 ปีที่แล้ว
Type Definition Population กลุ่มประชากร ทั้งหมดที่เราสนใจศึกษาSample กลุ่มตัวอย่าง ที่สุ่มมาจากประชากรSampling กระบวนการในการเลือก กลุ่มตัวอย่างจากประชากรGeneralization การนำผล ที่ได้จากการศึกษากลุ่มตัวอย่าง ไปอ้างอิง ถึงประชากร
โดย สถิติมักเริ่มจาก population หรือประชากรทั้งหมด
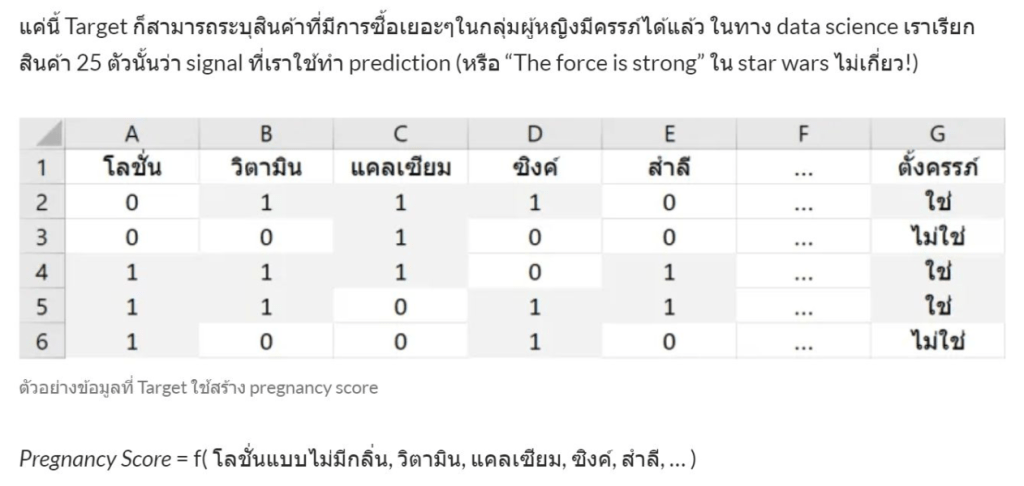
Case analysis of listening to Lisa’s music โดยประมาณคนไทยว่ามี 70 ล้านคน ถ้าอยากรู้คนไทยฟังชอบเพลง lisa กี่คนต้องทำยังไงบ้าง
การที่จะเข้าถึงคนไทย 70 ล้านคนเป็นไปไม่ได้เลย จึงสามารถวัดความชอบ ว่าคนไทยชอบเพลง lisa มั้ยสามารถวัดได้โดยสุ่มตัวอย่างขึ้นมา Sample Sampling
หากสุ่มตัวอย่างมา 100 คน โดยหากต้องรู้ว่าการสุ่มแบบไหนสามารถ Represent Generalization
สิ่งสำคัญที่สุดคือ วิธีการสุ่มตัวอย่าง แบบไหนถึงจะตัวอย่างที่ represent ประชากรที่ถูกกลุ่ม และมีคุณภาพ
Started Statistic
Small Data —> Big Data
เป็นศาสตร์การเรียนรู้ที่เกิดจากกลุ่มตัวอย่างที่ถูกสุ่มขึ้นมา เพราะทุกคนไม่มีใครสามารถเข้าถึงทุกข้อมูลในโลกใบนี้จึงมีการสุ่มตัวอย่าง ขึ้นมา
Sample Statistical Case Case Cooking Food Method
อย่างเช่นการทำกับข้าว โดยการตั้งคำถามเกี่ยวกับน้ำแกง สามารถถามอะไรได้บ้าง
เช่นซุปเห็ด ทำยังไงให้รสชาติออกมาอร่อย
ถ้าอยากรู้ว่าซุปเห็ดสับอร่อยโดยการใช้ช้อนในการชิมสุ่ม Sampling มาเพื่อชิมรสชาติ
หากชิมแล้วอร่อย จะสามารถสรุปผลกลับไปยังทั้งหม้อ ได้เลยว่า ทั้งหม้ออร่อยด้วย
Case Mushroom Soup Case Stock
หากมีหุ้นชนิดหนึ่งที่เราต้องการลงทุนซื้อ จำเป็นต้องศึกษาข้อมูลของบริษัทด้วย
Case Stock
เราสามารถรู้ว่าข้อมูลได้บางอย่างจากบริษัทเหล่านั้น ซึ่งเหล่านั้นมาจากข้อมูล Sample
เราสามารถทำ Sampling กลับหาหุ้นได้เลยว่า หุ้นตัวนี้จะมีแนวโน้มที่ดีขึ้นจากข่าวอะไรได้บ้าง บริษัทมีผลประกอบการณ์เป็นอย่างไรบ้าง ส่งผลต่อหุ้นมั้ย
Case Relationship
สมมุติผู้หญิงคนหนึ่งคุยกับผู้ชายคนหนึ่งอยู่จะรู้ได้ไงว่า ผู้ชายที่คุยอยู่เป็นคนดี มั้ย
เริ่มถามเพื่อนของผู้ชายว่า ผู้ชายที่เรากำลังคุยอยู่โอเคมั้ย
ผู้ชายคุยกับผู้หญิงหลายคน
หน้าที่การงานของผู้ชาย
ผู้ชายกินเหล้าสูบบุหรี่
หากเก็บข้อมูล มา 3 เดือนจะสรุปได้ว่าคนนี้โอเคที่จะคบกันเป็นแฟน ได้
Case Relationship Things to watch out for in a relationship
ตอนเก็บ Sampling ผู้ชายคนนี้ 3 เดือนแรกดีกับเรา หมดเลย ซื้อ Chocolate ซื้อดอกไม้ ให้ของขวัญ ถูบ้าน ซักผ้าให้
ช่วงหมดโปรผ่านไป 3 ปีอาจจะไม่เหมือนเดิม เพราะหมดช่วงโปรสิ่งเหล่านั้นจะน้อยลงด้วยเคยชิน
โดยที่เราไม่รู้จักคนที่คุยด้วยดีพอจนกว่าจะต้องไปตื่นเจอกันทุกเช้าเพื่อที่จะสามารถรู้ว่า lifestyle เข้ากันได้หรือเปล่า
อย่างเช่น ตอนนอนต่างคนต่างกรนจนรำคาญกัน
คู่ชีวิตเรา มองข้อเสียของกันแล้วรับกันได้มั้ย แต่ที่มีคู่ชีวิตก็ดีสามารถเป็นกระจกเพื่อส่องข้อดี ข้อเสียของอีกฝ่ายได้
Sampling Type of Sampling Definition Probability Samplingการสุ่มแบบใช้ความน่าจะเป็น Non-Probability Samplingการสุ่มแบบไม่ใช้ความน่าจะเป็น
ในชีวิตจริง เรามักใช้การสุ่มแบบใช้ความน่าจะเป็น มากกว่า
Probability Sampling Simple Random Sampling การสุ่มตัวอย่างแบบง่าย คือ การสุ่มตัวอย่างที่สมาชิกทุกคนในประชากรมีโอกาสเท่าๆกัน ในการถูกเลือกเข้ามาเป็นกลุ่มตัวอย่าง
Benefits of Probability Sampling
หากจะใช้กระบวนการนี้ ต้องมีรายชื่อคนไทยทุกคนอยู่ใน program R หรือ Spreadsheet แล้วสุ่มตัวอย่างมา 400 คน
Simple random Sampling ทำได้กับระบบปิดเท่านั้น คนใน Community Discord 400 คน โดยสุ่ม 40 คนเพื่อดู model ว่า แอดทอยสอน Data ใน Discord มั้ย
Case Lottery
เช่น สุ่มคง 100 คนจากคน 1 คน ทุกคนมีโอกาสถูกสุ่มเข้ามา 1%
จับการรางวัล lottery โอกาสได้เบอร์ 0.1% เพราะมีเบอร์ 0-9
Case Lottery Case Samsung
Samsung ลดจากการ WFH 1 วันต่อสัปดาห์ —> WFH 1 วันต่อ 2 สัปดาห์ เพราะไม่ได้ติดโควิดเหมือนสมัยก่อน
ตัวอย่างเช่นนโยบาย ที่อยากให้ตรวจสอบว่าพนักงาน 3000 คนบริษัทอยาก WFH มั้ยจึงสุ่มสำรวจในแผนก 30 คนเพื่อ Refer ถึงพนักงานโดยรวมเพื่อทราบว่าพนักงานต้องการ WFH มากแค่ไหน
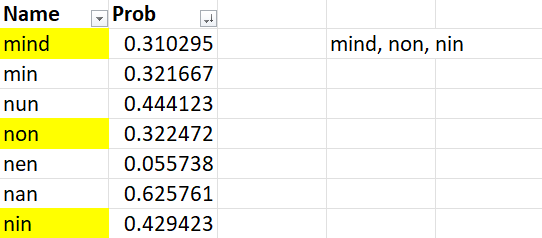
Case Simple Random Sampling in Excel สมมุติการสุ่มแต่ละครั้งโดยเลือก 3 คนจาก 5 คใน Excel ดังนี้
Case Simple Random Sampling in Excel
แต่ในความจริงถ้าจะทำสุ่มประชากรของประเทศไทย ต้องมีรายชื่อทั้งหมด 70 ล้านคนแล้วสุ่มจึงทำยาก
Facebook สามารถทำ Random Sampling ได้เลยเนื่องจากมีข้อมูลลูกค้าที่อยู่ในประเทศนั้นๆ
โดย Survey ที่ brand ในแต่ละประเทศได้รับจะโอเคเพราะมีข้อมูล User เยอะ
Systematic Random Sampling
เป็นการสุ่มแบบมีระบบที่วางไว้หรือเป็น pattern ตั้งไว้ โดยเลือกสุ่ม 3 คน
อยากสุ่มคนที่ 1 แล้ว เว้นการสุ่ม 2 คน หลังจากนั้นสุ่มคนที่ 4 ทำแบบนี้ไปเรื่อยๆ จนเป็นระบบดังรูปด้านล่าง
Case Systematic Random Sampling Cluster random Sampling
เป็นการแบบสุ่มแบบแบ่งกลุ่มไว้ก่อน 3 กลุ่ม แล้วสุ่มตาม Cluster
สุ่มเลข 1 ถึง 3 หากสุ่มได้ Cluster ไหนก็ให้เลือก Cluster ในการสุ่มตัวอย่างทำ Survey
Case Cluster random Sampling Stratified Random Sampling เป็นวิธีการสุ่มตัวอย่างที่แบ่งประชากรออกเป็นกลุ่มย่อยๆ (strata) ตามลักษณะที่สนใจ (เช่น เพศ อายุ ระดับการศึกษา) แล้วสุ่มตัวอย่างจากแต่ละกลุ่มย่อย โดยแต่ละกลุ่มย่อยจะมีสัดส่วนเท่ากับสัดส่วนในประชากร
Stratified Random เป็นวิธีการที่มีใช้ในงาน Market & Research เยอะที่สุด
Case Beer
อยากรู้ว่าคนไทยชอบ กินเบียร์ กี่คน ให้สุ่มจากคน 1,000 คน
Sample size จะถูกจำกัดด้วย 2 เรื่องคือ Time and Budget
Calculate Budget
เช่นมีงบการเงิน 500,000 บาท
Cost Per Interview = 500,000/1,000 = 500 บาทต่อคน แล้วคำนวณว่าเป็นไปได้มั้ยโดยที่เราจะต้องคำนวณ Margin ให้กำไร 40-50%
เช่น CPI 500 บาทต่อคน ค่าทำ Survey ควรจะ 250 บาทต่อคน
Cost Per Interview คือ ต้นทุนต่อการสัมภาษณ์หนึ่งครั้ง
Method
แบ่งประเทศเป็น 5 ภาคดังนี้
Sector Percentage Northern Region 10% Northeastern Region 35% Southern Region 15% Central Region 30% Bangkok and Metropolitan Area 10%
แล้วกลับไปเสนอลูกค้า 1000 คนไปเสนอตามสัดส่วนในที่แบ่งตามเขตไว้
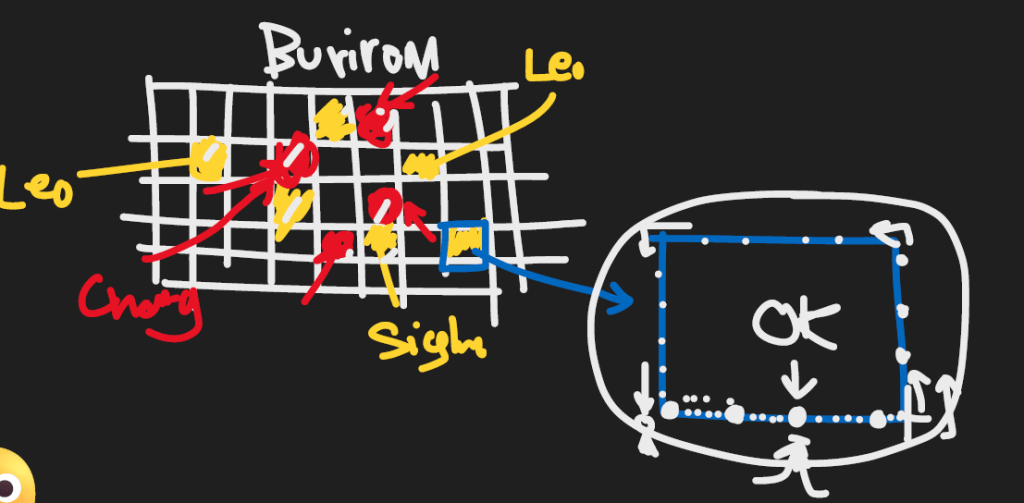
เก็บข้อมูลจากจังหวัดที่ลูกค้าเยอะๆ เช่น ภาคอีสาน เก็บข้อมูลจากจังหวัดขอนแก่น จังหวัดบุรีรัมย์ จังหวัดโคราช, ภาคเหนือ จังหวัดเชียงใหม่
แล้วจะมีแผนที่ของแต่ละจังหวัดเป็นตาราง Grid ของจังหวัดบุรีรัมย์
Case Grid 4. ใช้โปรแกรม Computer สุ่มเลยว่าอยากไปเดินสุ่มที่ Block ไหนของตาราง Computer
The reality of customer interactions
แต่เมื่อเอา plan ไปเสนอลูกค้าที่เป็นการสุ่มเลือกพื้นที่สีเหลือง ลูกค้าเลือกพื้นที่สีแดง เลย
ที่โปรแกรม Computer ในการสุ่มเลือกพื้นที่ต่างๆ ต้องการลดการ bias ในการเลือกพื้นที่
ลูกค้าอยากเลือกพื้นที่เองเพราะลูกค้า Brand Chang อยากเลือกพื้นที่ที่หนีพื้นที่สีเหลือง ที่คู่แข่งเก่งเช่น Leo กับ Singha
โดยทีม Research จะต้องพยายามเลือกทั้งจังหวัดที่ Brand Chang เก่งและจังหวัดที่เราไม่เก่งด้วย เพื่อสร้างสมดุลในการเลือก Sample Size
เวลาที่เก็บข้อมูลจริง จะใช้หลักการ Left hand Rule เวลาสัมภาษณ์หลังที่ 1 แล้วก็กระโดดสัมภาษณ์ 4 หลังแล้วสัมภาษณ์ต่อดังรูปสีฟ้า
Case Population Census เริ่มจากไป Search ในสำนักงานสถิติแห่งชาติ
รัฐบาลจะทำ Survey ว่า
คนไทยมีจำนวนกี่คน
ผู้ชายกี่คน ผู้หญิงกี่คน คนไทยทำอาชีพอะไร
คนไทยมีความสุขในการใช้ชีวิตมั้ย
10 ปีจะทำ Survey ครั้งนึงโดยการทำถาม Survey ตามบ้าน โดยมีการทำสำมะโนประชากรครั้งล่าสุดปี 2553
Case Population Census สิ่งที่น่าเศร้าคือหน่วยงานรัฐบาลไม่ทำแล้วให้หน่วยงานเอกชนเป็นคนทำแทน Survey 2568
Non Probability Sampling Convenience Sampling
เป็นวิธีการสุ่มตัวอย่างที่ไม่ต้องอาศัยหลักการทางสถิติที่ซับซ้อน แต่เน้นความง่ายและความสะดวกในการเข้าถึงกลุ่มตัวอย่าง
เช่น สร้าง Suvery เป็นแบบสอบถามให้คนกรอก google form
Case Google Form
เป็น Case ที่เด็กปริญญาโทมักจะต้องเก็บข้อมูลเพื่อทำวิจัย Project ต่างๆ
Method
เก็บ Sample Size 400 คน เป็นคนกรุงเทพ
อายุ 20-35 ที่ชอบซื้อออนไลน์
ส่วนใหญ่มักมีการเก็บข้อมูลผ่านการส่งให้เก็บข้อมูลทาง line และ facebook
ข้อควรระวัง : แต่ถ้าให้เก็บข้อมูลผ่านเพื่อนๆ เช่น เด็ก ผู้หญิง จบโรงเรียนหญิง คนทำแบบทดสอบที่มักจะมาจากผู้หญิง
Type Men Percentage Women Percentage Population 50% 50% Sampling 20% 80%
หากจะเลือก Sample Size สุ่มให้ดี ควรเลือกกลุ่มที่มีความใกล้เคียง Population เช่นเลือกคนที่เป็นคนตอบแบบสอบถามให้ใกล้เคียง Population เช่น Sampling ควรมีผู้หญิง และผู้ชายเท่ากับ Population
Sampling ที่สุ่มมาได้ผู้ชาย 20% ซึ่งไม่ตรงกับ Population ซึ่งทำให้ใช้จริงได้ยาก
Cautions
ทำให้ Sample ไม่สามารถ Represent กับ Population ที่เกิดขึ้นจริงได้
สาเหตุมาจากวิธีการสุ่มตัวอย่างที่เรียก Convenience Sampling เพราะสุ่มตามที่เราสะดวก
Snowball Sampling การหากลุ่มตัวอย่างเริ่มต้นจำนวนเล็กน้อย จากนั้นให้กลุ่มตัวอย่างเหล่านั้นแนะนำสมาชิกคนอื่นๆ ในกลุ่มเป้าหมายเดียวกัน
Case Ivory Case Ivory WWF
ทำไมคนไทยถึงซื้องาช้าง?
เพราะซื้อมาประดับบารมี
ซื้อเพื่อโชว์ฐานะทางบ้าน
ซื้อเพื่อความเชื่อบางอย่างและหน้าที่การเงิน
เนื่องจากไม่รู้ว่าจะเก็บข้อมูลจากลูกค้ามาจากไหน เนื่องจากปกติไม่ค่อยมีกลุ่มลูกค้าที่ซื้องาช้าง
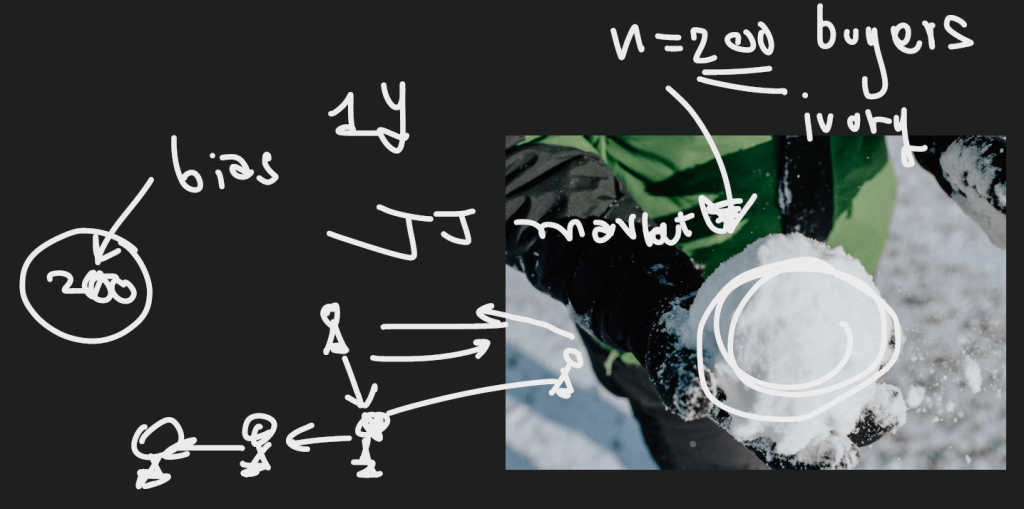
Case Snowball Sampling Method
ให้หาลูกค้า คนแรกที่ซื้องาช้าง ให้ได้ก่อน แล้วค่อยถามต่อไปเรื่อยๆ เป็น process
แล้วทำ Survey ในประเทศไทย 200 คน
ไปเก็บข้อมูล JJ market (Chatuchak) ที่ร้านขายงาช้าง แล้วสัมภาษณ์คนซื้องาช้างใน 1 ปีแล้วถาม ณ เวลานั้นเลย แล้วขอ Contact คนซื้องาช้างจากลูกค้าต่ออีกที เหมือนกับการโยนหิมะใส่กันไปเรื่อยๆจึงเรียก Snowball
ได้กลุ่มตัวอย่างมา 200 คน แต่กลุ่มคน 200 คนนี้ความเห็นจะคล้ายๆกัน เพราะเป็นเพื่อนกันเลยขาดความหลากหลายของข้อมูล
Data Collection
เก็บ data ที่มีคุณภาพมาก่อนก็จะช่วยให้ได้การวิเคราะห์ข้อมูลที่มี make sense และถูกต้องมากยิ่งขึ้น
คำถามแรกที่มักถูกถามคือ ข้อมูลมาจากไหน project data ที่เรามาจากไหน
ถ้าลูกค้าไม่เชื่อกระบวนการเก็บ data ของเรา โอกาสที่ขายงานผ่านจะน้อยมาก
ถ้าไม่เข้าใจวิธีการเก็บ data ที่ดีอาจจะทำให้การวิเคราะห์ data แบบ Regression ตั้งแต่แรกผิดไปเลยก็ได้
ถ้า Sample ไม่ Represent Population ก็อาจจะไม่ต้องทำต่อเลยก็ได้
Sample Size Sample Size Method
สุ่มแบบที่ 3 n=300 คนจะได้ผลลัพธ์ที่ดีในการสุ่มแบบ Random Sampling
ยิ่ง Sample Size เยอะ จะยิ่งได้ผลลัพธ์ดี ขึ้นเท่านั้น
n จำนวนเยอะ Quality ก็เยอะ ยิ่งเข้าใกล้ population
สามารถคำนวน Sample Size ได้จาก Website นี้
Variable Definition Calculate Population size จำนวนทั้งหมดของกลุ่มคนที่คุณสนใจศึกษา 1000 Confidence level ความน่าจะเป็นที่ผลการสำรวจของคุณจะสะท้อนความเป็นจริงของประชากรทั้งหมด 95% Margin of error ช่วงความคลาดเคลื่อนที่ยอมรับได้ของผลการสำรวจ 5
Calculate sample size Confidence level ถ้าทำ Survey นี้ซ้ำ 100 ครั้ง จะมี 95 ครั้งได้ผลลัพธ์เหมือนเดิม เป็นระดับความเชื่อมั่นจากการทำซ้ำ
ยิ่งทำซ้ำเยอะๆ ก็ยิ่งได้ผลลัพธ์ที่มั่นใจขึ้นเรื่อยๆ
Margin of error ค่าความคลาดเคลื่อนจากคนที่สุ่ม 278 อาจจะมีคนเห็นด้วย 70% ไม่เห็น 30% แล้วความคลาดเคลื่อนที่ขึ้นจาก 70% ที่ว่ามีคลาดเคลื่อน +-5% = [65%,75%] ได้เป็น lower bound และ upper bound
ยิ่งความคลาดเคลื่อนของข้อมูลน้อยลง ก็จะสามารถได้ข้อมูลที่แม่นยำขึ้น
Margin of Error vs Sample Size
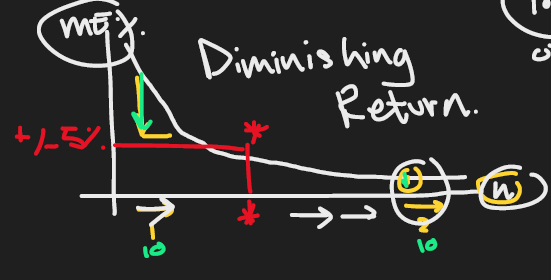
Margin of Error vs Sample Size Diminish Return Diminish Return Diminish Return สำหรับการเก็บข้อมูล ถ้ายิ่งเก็บ sample size เพิ่มทุกๆ 1 คน จะลด Error ในอัตราที่น้อยลงเรื่อยๆ
เปรียบเสมือนกับ 1 ชั่วโมงแรกเราฝึกขี่จักรยานจะเก่งขึ้นก้าวกระโดดเพราะไม่เคยฝึก
แต่ฝึกขี่จักรยานชั่วโมงที่ 2 จะเก่งขึ้นน้อยกว่าชั่วโมงแรก เพราะเรามีพื้นฐานขี่จักรยานเลยเก่งขึ้นน้อยลงกว่าตอนฝึกชั่วโมงแรก
นักสถิติคิดไว้แล้วว่าหยุดที่ Margin of Error 5% ที่เส้นสีแดงเพราะคุ้มค่าที่หยุดเก็บ Sample Size เพิ่มแล้ว
ถ้าเราเก็บ n เยอะขึ้น ก้จะมีต้นทุนค่าใช้จ่ายเยอะขึ้น
Margin of Error vs Sample Size vs Budget Margin of Error vs Sample Size vs Budget Margin of Error Sample Size Budget 5% 278 278,000 3% 517 517,000
หากใช้ Margin of Error 5% – 3%=2% จะมีค่าใช้จ่ายเพิ่ม 517,000-278,000 = 239,000 บาท
ในความจริงถ้าบอกลูกค้าว่าลด Error 2% มีค่าใช้จ่ายเพิ่ม 239,000 บาท แล้วแจ้งลูกค้าอาจจะไม่ยอมจ่าย เพราะราคาแพงเกินไป
ความเป็นจริงลูกค้าเลือก Margin of Error 5%
ค่า Margin of Error 5% ภาษาอังกฤษเรียก Arbitary ไม่ได้มีค่าตายตัว
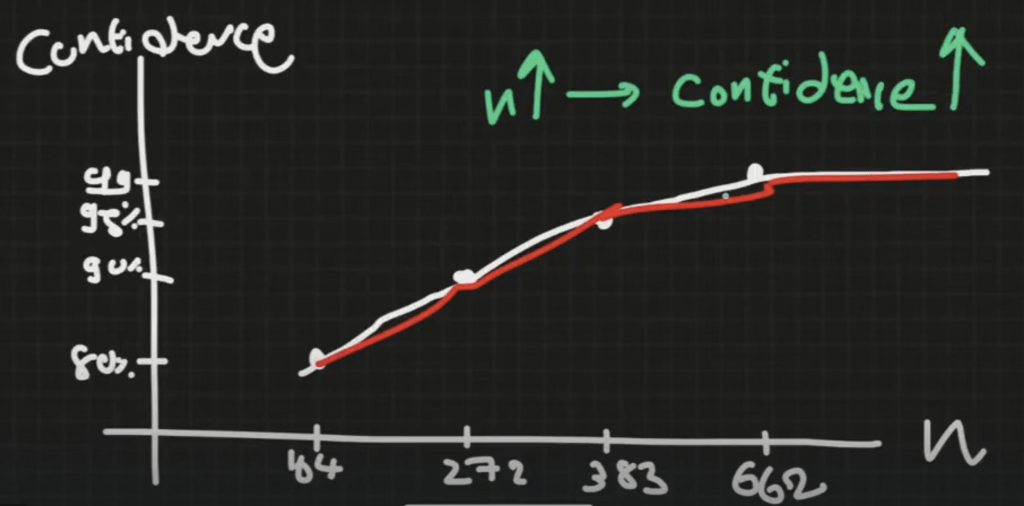
Confidence Level vs Sample Size Confidence Level vs Sample Size
Confidence Level แปรผันตรงกับ Sample Size
Sample size = data
ถ้าอยากตัดสินใจได้ดีขึ้นเรื่อยๆ ก็ควรจะเก็บ Data เยอะขึ้นเรื่อยๆ
ถ้าอยากมี Career ที่ดีก็ต้องเรียนรู้ไปเรื่อยๆเลย อนาคตถึงจะสดใส
ใครที่มีความรู้ที่อยู่ในหัวเยอะและเป็นข้อมูลที่มีคุณภาพก็จะเติบโตไปข้างหน้าได้ดีกว่าคนอื่น
Recommend Statistic book : Naked Statistics
Descriptive Stat
ใช้ในการอธิบายค่าต่างๆ ที่สุ่มขึ้นมาจาก Sample
เช่นใช้ค่า Mean, Median, Mode ในการวัดค่ากลางของ Sample Size
Central tendency
การวัดค่ากลางของข้อมูล ควรเริ่มจากการเรียงข้อมูลเพื่อหาค่าเหล่านั้นได้ถูกต้อง
Central Tendency Mean ค่าผลรวมของเลขทั้งหมด/จำนวนของเลขทั้งหมด
ค่าเฉลี่ย = (5+10+10+15+22)/5 = 12.4
ค่าตรงกลางของข้อมูล เช่น 5 10 10 15 22 ค่าที่อยู่ตรงกลางสุดคือ 10 เลข 10 จึงกลายเป็น Median
Mode ค่าซ้ำมากสุดของข้อมูล เช่น 5 10 10 15 22 ค่าที่ซ้ำมากสุดคือ 10 จึงกลายเป็น Mode
หากตัวเลขซ้ำกันมากกว่า 1 ตัวเช่น 5 10 10 15 15 ค่าที่ซ้ำมากสุดคือ 10 , 15 จะเรียกว่า Bimodal
Case Study supermarket เช่นคนจะเข้าไปซื้อของกินที่ Supermarket กันในช่วงเวลา กลางวัน และเย็น เยอะ จึงกลายเป็นช่วงที่โดดเด่นจึงเรียกว่า Bimodal
Multimodal AI can process virtually any input , including text, images, and audio เนื่องจากสามารถ create 3 อย่าง พร้อมกันได้จึงกลายเป็น Multimodal
Spread Tendency Type Definition SD (variance) การกระจายตัวของข้อมูล Range max – min = ค่ามากสุด – ค่าน้อยสุด (พิสัย)
Standard Deviation Formula Position Type Definition Min ค่าต่ำสุดของข้อมูล Max ค่าสูงสุดของข้อมูล Percentile ค่าของข้อมูล ณ จุด 99 จุด ที่แบ่งข้อมูลซึ่งเรียงจากน้อยไปหามากออกเป็น 100 ส่วน โดยที่แต่ละส่วนมีจำนวนข้อมูลเท่า ๆ กัน
ถ้าคุณสอบได้คะแนนอยู่ในเปอร์เซ็นไทล์ที่ 80 หมายความว่าคุณได้คะแนนสูงกว่า 80% ของผู้สอบคนอื่นๆ ทั้งหมด
Process of Distribution process ที่นักสถิติมี 2 วิธี ใช้ตัวเลขและกราฟในการวิเคราะห์ข้อมูล
Numerical ตัวเลขGraphical กราฟ
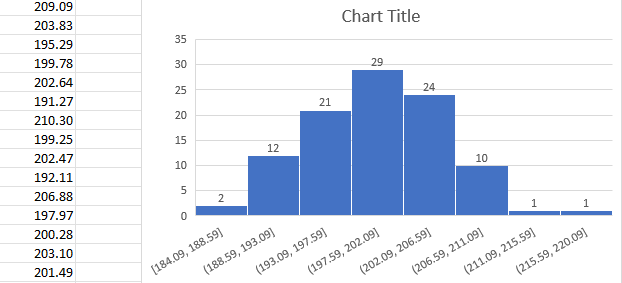
Histogram Graph
หลังสุ่มตัวเลขมา 100 เลขแล้วสามารถสร้าง Histogram ได้ดังรูปครับ
จะสามารถได้ผลลัพธ์ที่มีการแจกแจง 3 แบบดังนี้
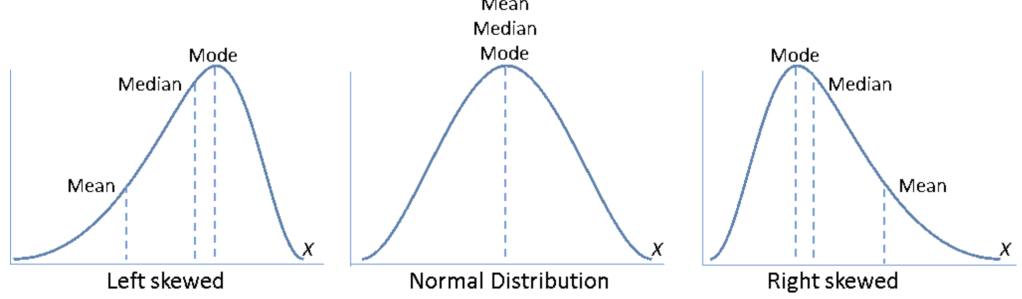
Type Graph Relation Sample Normal Distribution กราฟรูประฆังคว่ำ สมมาตร Mean = Median = Mode คะแนนสอบที่มีการกระจายตัวดี Skewed Left Distribution หางยาวไปทางซ้าย Mean < Median < Mode คะแนนสอบที่นักเรียนส่วนใหญ่ได้คะแนนสูง Skewed Right Distribution หางยาวไปทางขวา Mean > Median > Mode คะแนนสอบที่นักเรียนส่วนใหญ่ได้คะแนนต่ำ
3 Distribution
Technique หางของกราฟไปทางฝั่งไหน ให้เบ้ไปทางฝั่งนั้น
ถ้าข้อมูลมีการเบ้ เรามักจะใช้ค่า Median ในการวัดค่ากลาง
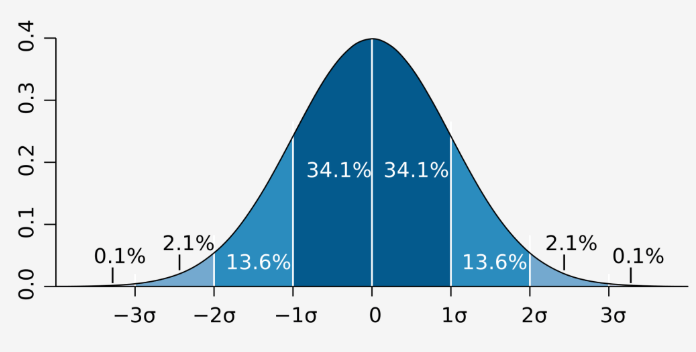
Normal Distribution
(Bell Shape Curve) การกระจายตัวปกติ
โดยพื้นที่ใต้กราฟมีค่าเป็น 1
Normal Distribution Area under the graphPercentage 1 SD 68.2% 2 SD 95% 3 SD 99.7%
Skewed Left Distribution
อย่างเช่นมีการสอบแล้วนักเรียนลืมไปสอบ 5 คนทำให้คะแนนสอบลดลงไปเยอะ
หากมีนักเรียนไม่ได้สอบ 5 คนจะทำให้ค่า Mean ตกจาก 66 คะแนน เป็น 52 คะแนน
Skewed Left Distribution Skewed Right Distribution คนรวยมีจำนวนน้อย คนจนมีจำนวนมาก จะเบ้ขวา
สามารถเช็ค Thailand GDP per Capita link
GDP = เอารายได้คนทั้งประเทศ / จำนวนคนทั้งหมด = mean
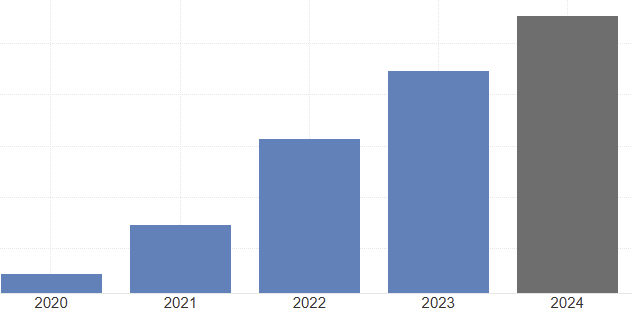
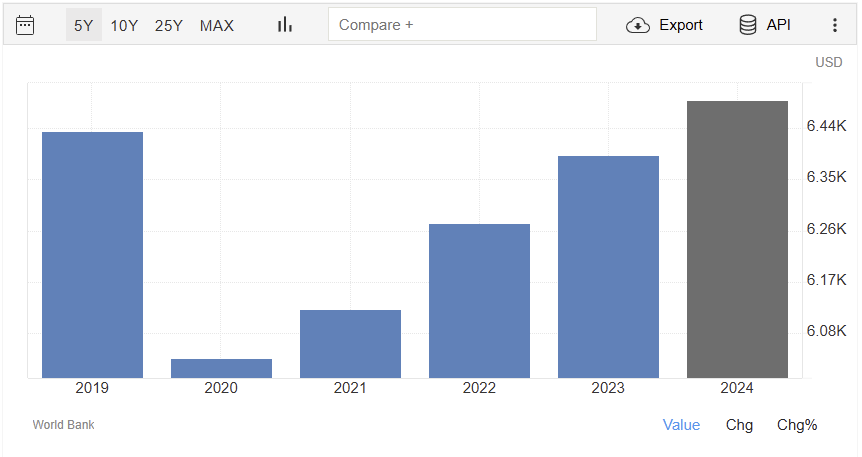
Prepare Two Graph
2020-2024 GDP
2019-2024 GDP
ถ้าดูแค่กราฟแรก รายได้เพิ่มมา 500 เหรียญในรอบ 5 ปี เพราะคนรวยในประเทศรายได้เพิ่ม
หากนับปี 2019 ก่อนเกิดโควิดจะเห็นได้ว่ารายได้ในประเทศในรอบ 5 ปี ไม่เพิ่มเลย เราแค่มีรายได้กลับมาใกล้กับปีที่มี 2019
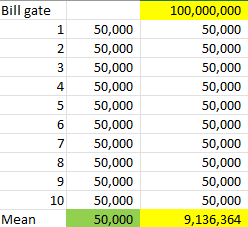
Outlier Outlier Method
ตอนแรกค่าเฉลี่ยคนในประเทศอยู่ 50,000 บาท 10 คน แต่มี Bill gate เพิ่มเข้ามาจะทำให้ค่าเฉลี่ยเพิ่มขึ้นจาก 50,000 บาท เป็น 9,136,634 บาท
การเพิ่มเข้ามาของ Bill Gate เรียกว่า Outlier
จึงเป็นสาเหตุให้รายได้ของประเทศมีการกระจายตัวเบ้ขวาเพราะคนรวยเพิ่มมาบางคนทำให้ค่าเฉลี่ยนในประเทศเปลี่ยนไปมาก
Case Singapore GDP
ที่ Singapore GDP สูง แต่คนในประเทศลำบากเช่นค่าน้ำ 60 บาท
GDP per capital ไม่สื่อถึงการกระจายรายได้ แต่ยังใช้ค่าเฉลี่ยอยู่ เพราะยังหาวิธีที่ดีกว่าไม่ได้
GDP เท่าเดิม แต่คนในประเทศ 90% สามารถมีความสุขได้โดยการที่คนรายได้สูง 10% ของประเทศ ยอมจนลง 10% กระจายรายได้ของคนในประเทศนี้จะดีขึ้นได้ตามรูปด้านล่าง
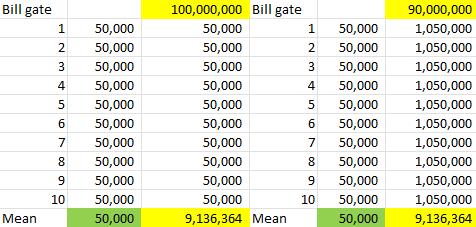
หาก bill gate แบ่งเงินรายได้ 10% คนในประเทศรายได้ขึ้นหลายเท่าได้เลย
หาก Bill Gate แบ่งเงินรายได้ 10% คนในประเทศรายได้เพิ่มขึ้นหลายเท่าได้เลย
หวังว่าการบทความสรุปเกี่ยวกับสถิติและเคสตัวอย่างที่ยกตัวอย่างไป จะสามารถนำไปประยุกต์ใช้ในชีวิตประจำวันแล้วทำให้ตัดสินใจดีขึ้นโดยอ้างอิงสถิติทางทฤษฎีไปสู่ชีวิตจริงครับ
ขอบคุณคอร์ส Essential Statistic 1 จาก Data Science Bootcamp 11 DataRockie : https://data-science-bootcamp1.teachable.com/courses/enrolled/2684443